
Scientific journal
European Journal of Natural History
ISSN 2073-4972
ИФ РИНЦ = 0.204
FOG TIPE FORECASTING AT PULKOVO AIRPORT USING ARTIFICIAL NEURAL NETWORKS

Туман – это видимый аэрозоль, который состоит из маленьких капель воды и кристаллов льда, взвешенных в воздухе у поверхности Земли и на ней, продолжительность этого опасного явления может достигать нескольких часов, а в холодное время года и нескольких суток.
В синоптической практике прогнозисты используют разные методы, в том числе опираются и на численные методы прогноза погоды.
Целью работы является построение такой модели на основе алгоритмов глубокого обучения, которая сможет с высокой точностью спрогнозировать тип тумана. Это облегчит работу синоптикам и повысит уровень качества прогнозов этого опасного явления.
1. Микроклимат аэродрома
Одной из особенностей микроклимата Санкт-Петербурга является повышенная влажность – около 80% (летом – 60–70%, зимой – 83–88%). Число дней с относительной влажностью не менее 80% варьируется от 140 до 155 [1]. Для района Аэродрома характерна большая повторяемость воздушных масс атлантического происхождения. Активная циклоническая деятельность и частая смена воздушных масс определяют неустойчивый характер погоды во все сезоны.
Согласно климатическому описанию Аэродрома Пулково наиболее часто туманы наблюдаются с августа по октябрь с максимальной среднемесячной повторяемостью в сентябре (10,9%), а реже всего туманы наблюдаются в январе (в среднем 1,1%) [1]. При анализе повторяемости туманов за каждый месяц можно выделить теплый (май – октябрь) и холодный периоды (ноябрь – апрель) года.
В авиационной практике используются следующие обозначения различных типов тумана:
1) FG (Fog – туман) – скопление в воздухе очень мелких капель воды, образующихся в результате охлаждения влажного воздуха, которое приводит к уменьшению горизонтальной видимости менее 1000 м.
2) FZFG (Freezing fog – переохлажденный туман) – замерзающий туман состоит из переохлажденных капелек.
3) MIFG (Shallow fog – поземный туман) – используется, когда наблюдаемая горизонтальная видимость составляет 1000 м или более. Однако, в слое между уровнем земли и 2 м над землей (на предполагаемом уровне глаз наблюдателя) существует слой, в котором истинная видимость составляет менее 1000 м.
4) BCFG (Patches fog – туман клочьями) – указывает на наличие обрывков тумана, беспорядочно покрывающих аэродром.
5) PRFG (Partial fog – частичный туман) – значительная часть аэродрома покрыта туманом, а на остальной части туман отсутствует. Видимость в тумане должна быть менее 1 000 м, при этом туман распространяется, по меньшей мере, до высоты двух метров над землей [2-4].
Данные из архива аэродрома Пулково (г. Санкт-Петербург) о наблюдении различных типов туманов были предоставлены Северо-Западным филиалом ФГБУ «Авиаметтелеком Росгидромета». Период наблюдений с 1 января 2010 года по 8 февраля 2022 года [5].
2. Алгоритмы глубокого обучения и нейронные сети
Нейронный подход к глубокому обучению основан на двух главных идеях. Первая мысль заключается в том, что мозг – это доказательный пример возможности разумного поведения. Поэтому построение ИИ основано на анализе принципов работы мозга и на воспроизведении его функций. Вторая идея состоит в желании людей понять, как работает мозг человека и какие принципы лежат в основе разума. Поэтому модели на алгоритмах глубокого обучения полезны вне зависимости применения их к инженерным задачам.
Существует большое количество видов нейронных сетей, которые отличаются между собой архитектурой, особенностями функционирования и сферами применения. Для исследования была выбрана полносвязная многослойная нейронная сеть, ее структура отображена на рисунке 1.
Такие многослойные сети обладают определенными отличительными свойствами. Каждый нейрон имеет гладкую (всюду дифференцируемую) нелинейную функцию активации, сеть содержит один или несколько слоев скрытых нейронов, не являющихся частью входа или выхода сети, и обладает высокой степенью связности, реализуемой посредством синаптических соединений. Учитывая все эти свойства и способность к обучению на собственном опыте нейронная сеть обеспечивает высокую вычислительную мощность. Такой вид сеток имеет достаточную точность и скорость для прогнозирования временных рядов.
Многослойные нейронные сети содержат множество входных узлов, которые образуют входной слой. В данной задаче такими узлами являются – скорость ветра (м/с), направление ветра (градусы), порывы ветра (м/с), видимость (м), общая облачность (баллы), облачность нижнего яруса (баллы), высота нижней границы облачности (м), температура воздуха (°С), температура точки росы (°С), давление (гПа) и рассчитанная характеристика на основе данных – дефицит точки росы (°С). Внутри сетки находится несколько скрытых слоев вычислительных нейронов, где и происходит основная работа. Последний слой называется выходным, в данной задаче он содержит вероятность возникновения 5ти видов тумана на аэродроме и прогноз видимости самого вероятного.
2.1 Алгоритм работы
Постановка задачи.
В данной работе необходимо произвести анализ данных, их обработку для того, чтобы в дальнейшем можно было их использовать в нужном формате.
Затем необходимо построить модель многослойной нейронной сети, описать границы слоев, их количество и размер, определить количество эпох обучения.
Последним этапом является обучение. Необходимо соединить модель, обработанные данные, затем учесть скорость обучения и оптимизировать минимизацию ошибок.
Препроцессинг.
На этом этапе как раз и происходит анализ и предварительная обработка данных, которые так необходимы для дальнейшей работы.
В этом блоке данные были поделены на 5 классов: туман, частичный туман, переохлажденный туман, туман клочьями и поземный туман. Затем из сырых данных были убраны ненужные элементы таблицы, произведена сортировка всех значений в зависимости от класса.
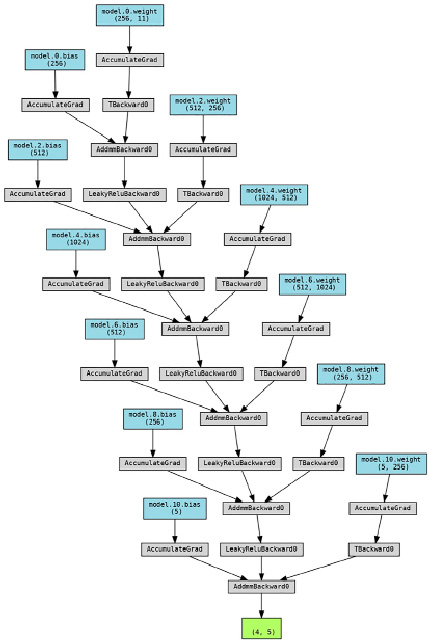
Рис. 1. Структура нейронной сети данного исследования
Затем была проведена предобработка входных данных нормализацией со средним 0 и среднеквадратичным отклонением 1. Это необходимо для того, чтобы упростить восприятие входных данных нейронной сетью и облегчить для нее процесс обучения (нормальное распределение).
Был создан массив данных, в который входили по 1645 значений метеорологических параметров по каждому типу тумана, был определены целевые значения на выход сетки (y). Далее данные были поделены для обучения и валидации, этот этап необходим для того, чтобы в дальнейшем результаты обучения можно было сравнить с контрольными значениями и сделать вывод о качестве прогнозов. На этом процесс подготовки данных был окончен.
Модель нейронной сети.
На этом этапе была смоделирована архитектура и параметры нейронной сети: 11 входных значений, 5 значений на выходе модели, 5 скрытых слоев сетки, количество нейронов на начальном и конечном слое – 256.
Далее был определен процесс наследия слоев и прописана функция активации Leaky ReLu.
ReLu возвращает значение х, если х положительно, и 0 в противном случае. По началу кажется, что эта функция линейная, но это не так. Математически ее можно представить в виде:
f(x) = x, при х > 0 (2.1)
Область допустимых значений от 0 до inf.
Функция ReLu позволяет активизировать не все нейроны, а их часть, что облегчает работу вычислительной машине. Такое свойство очень полезно использовать в глубоких сетках с огромным количеством нейронов.
Недостатком этой функции является то, что она возвращает 0 для отрицательных значений, так как градиент на этой части равен 0. Из-за равенства нулю градиента, веса не будут корректироваться во время спуска. Это означает, что пребывающие в таком состоянии нейроны не будут реагировать на изменения в ошибке/входных данных. Чтобы решить эту проблему функцию ReLu немного модифицировали – Leaky ReLu (рис.2).
Для нее задается выражение:
f(x) = 0,01x, при х < 0 (2.2)
В данной работе на вход подается 11 нейронов и очень большие объемы данных, поэтому используется именно функция Leaky ReLu, так как она не требует высокой вычислительной мощи.
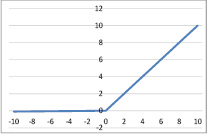
Рис. 2. Схема работы функции Leaky ReLu
Условия обучения
На этом этапе данные перемешиваются и форматируются в тензор, так как такой тип данных является входным условием пакета для машинного обучения в языке программирования Python. Далее 30% данных уходит на валидацию, а 70% на обучение.
Затем данные классифицируются методом кросс-энтропии, учитывается алгоритм адаптивной скорости обучения Adam и ставится значение количества эпох обучения (в данной модели 60).
Кросс-энтропия (или логарифмическая функция потерь) измеряет расхождение между двумя вероятностными распределениями. Если значение кросс-энтропии большое, то и разница между двумя распределениями большая и соответственно наоборот.
При кросс-энтропии рассматривается задача классификации входных данных двумя классами: 0 и 1. Для каждого параметра генерируется случайная величина, вероятность которой принимает значение 1 (p) и 0 (1-p). Используя метод максимального правдоподобия, функция записывается следующим образом:
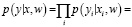
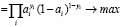 (2.3)
(2.3)
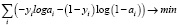 (2.4)
(2.4)
где 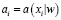 – ответ алгоритма, который зависит от параметров w, на i-м элементе.
– ответ алгоритма, который зависит от параметров w, на i-м элементе.
Когда функцию правдоподобия прологарифмировали, то получили, что его максимизация эквивалента минимизации.
Скорость обучения – это один из самых трудных для установки гиперпараметров, так как он напрямую влияет на качество модели. Для данной модели был выбран алгоритм с адаптивной скоростью обучения Adam.
Название «Adam» – сокращение от «adaptive moments» (адаптивные моменты) [6]. Точнее всего рассматривать этот алгоритм как комбинацию алгоритма RMSProp и импульсного метода, только с некоторыми отличиями. В Adam включен импульс в виде оценки первого момента (с экспоненциальными весами) градиента. Adam считается довольно устойчивым к выбору гиперпараметров, хотя скорость обучения иногда нужно брать отличной от предлагаемой по умолчанию (по умолчанию 0.001) [6].
Далее в работе был прописан цикл тренировки данных, где учитывается стохастический градиентный спуск, прямое и обратное распространение и считается общая функция потерь после каждой эпохи обучения.
Стохастический градиентный спуск – итерационный метод для оптимизации целевой функции с подходящими свойствами гладкости (например, дифференцируемость). Его можно расценивать как стохастическую аппроксимацию оптимизации методом градиентного спуска, поскольку он заменяет реальный градиент, вычисленный из полного набора данных, оценкой, вычисленной из случайно выбранного подмножества данных. Это сокращает задействованные вычислительные ресурсы и помогает достичь более высокой скорости итераций в обмен на более низкую скорость сходимости. Особенно важен в моделях, связанных с обработкой больших данных. Основной параметр алгоритма СГС – скорость обучения. Необходимо постепенно уменьшать ее со временем, поэтому будем обозначать εk скорость обучения на k-ой итерации. Метод СГС обновляет каждый параметр, вычитая градиент оптимизируемой функции по соответствующему параметру и масштабируя его на шаг обучения η, являющийся гиперпараметром. Если η слишком большой, то метод будет расходиться; если слишком маленький – будет сходиться медленно.
Достаточные условия сходимости СГС имеют вид:
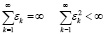 (2.5)
(2.5)
Если выбрана нейронная сеть прямого распространения, которая берет на вход x и вычисляет выход y, то данные передаются по такой сети только в одном направлении – вперед. Алгоритм обратного распространения помогает передать информацию в обратном направлении по нейронной сети для вычисления градиента. Алгоритм обратного распространения был разработан для того, чтобы избежать многократного вычисления одного и того же выражения при дифференцировании сложной функции, в противном случае скорость выполнения алгоритма возрастала экспоненциально [7].
В конце алгоритма прописываются параметры визуализации процесса обучения и вывода статистики для удобства восприятия процесса обучения сетки.
3. Результаты исследования
Как уже указывалось ранее, многослойные нейронные сети довольно трудно визуализировать, из-за наличия скрытых слоев. Поэтому результаты работы будут показаны в виде матрицы ошибок, которая представлена на рисунке 3.
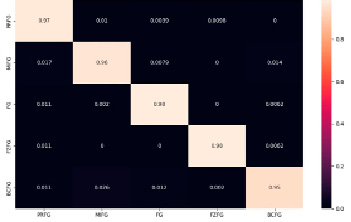
Рис. 3. Матрица ошибок, полученная в результате работы
Матрица ошибок представляет собой макет таблицы, который позволяет визуализировать точность алгоритма. Каждая строка является фактическим наблюдением, а каждый столбец прогнозом.
В результате работы получена матрица, имеющая размер 5х5 значений. Рассмотрим первый столбец. Первое значение в нем указывает на то, что модель спрогнозировала частичный туман и это верно с вероятностью 97%, остальные типы тумана в этом столбце верны с вероятностями менее 1%.
По результатам всей матрицы видно, что точность прогноза типов тумана составляет более 95%. Это говорит о том, что алгоритм глубокого обучения с использованием нейронных сетей построен верно и показывает очень высокие результаты.
Однако, при выполнении исследования возникли некоторые проблемы с тем, что данных оказалось очень мало. Именно это может объяснить почти идеальный результат прогноза. В дальнейшем модель требуется обучить на гораздо большем количестве данных, доработать прогноз видимости в данном типе тумана и прогноз времени наступления и окончания тумана.
Заключение
Уровень развития современной авиации позволяет в настоящее время выполнять полеты в различных условиях погоды, в том числе и в туманах. Однако до сих пор туманы являются одним из самых опасных явлений погоды для аэродромов. Качественный прогноз времени наступления тумана, видимости в нем и его продолжительности очень важен для многих служб аэродрома.
Результатом данного исследования является модель, построенная на алгоритмах высокого обучения, которая корректно работает и выдает хороший результат. Конечно, она требует доработки, но это уже большой шаг к повышению безопасности полетов и качества прогнозов.
Библиографическая ссылка
Кулижская П.В. ПРОГНОЗ ТИПА ТУМАНА НА АЭРОДРОМЕ ПУЛКОВО С ПОМОЩЬЮ НЕЙРОННЫХ СЕТЕЙ // European Journal of Natural History. 2023. № 1. ;URL: https://world-science.ru/en/article/view?id=34311 (дата обращения: 28.07.2026).